Finding Syntactic Structures from Human Motion Data
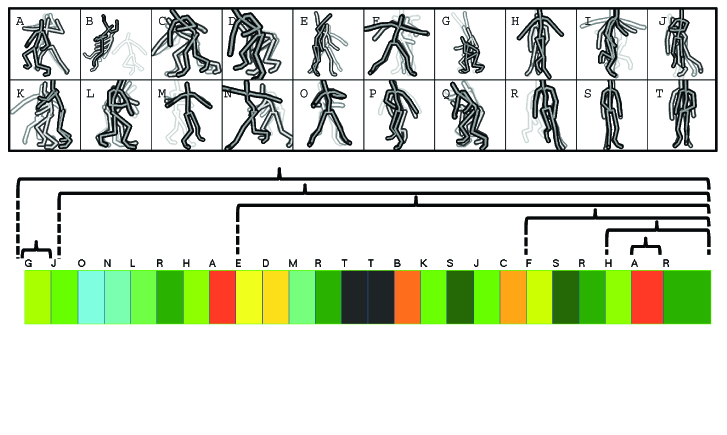
We present a new approach to motion rearrangement that preserves the syntactic structures of an input motion automatically by learning a context-free grammar from the motion data. For grammatical analysis, we reduce an input motion into a string of terminal symbols by segmenting the motion into a series of subsequences, and then associating a group of similar subsequences with the same symbol. In order to obtain the most repetitive and precise set of terminals, we search for an optimial segmentation such that a large number of subsequences can be clustered into groups with little error. Once the input motion has been encoded as a string, a grammar induction algorithm is employed to build up a context-free grammar so that the grammar can reconstruct the original string accurately as well as generate novel strings sharing their syntactic structures with the original string. Given any new strings from the learned grammar, it is straightforward to synthesize motion sequences by replacing each terminal symbol with its associated motion segment, and stitching every motion segment sequentially. We demonstrate the usefulness and flexibility of our approach by learning grammars from a large diversity of human motions, and reproducing their syntactic structures in new motion sequences.
Jong pil Park, Kang Hoon Lee and Jehee Lee
Finding Syntactic Structures from Human Motion Data
Computer Graphics Forum, to appear,